You are here

Combining multiple probes
We are almost halfway through the tutorial! If you can stick with it for this chapter, it should be downhill from here. If you're doing the tutorial for the first time and feel confused by some of the previous chapters, that's OK. I'm often confused myself. Just remember that the chapters will always be free and online. You can, and should, return to them at any time. The more time you spend on the fundamentals, the faster your research will progress later on.
I've promised that, by the end of this tutorial, you'll be able to infer vibration frequency, amplitude, and phase for each individual blade. To achieve this, we need to combine all AoAs belonging to the same blade together. This means combining the AoAs of the same blade at different proximity probes. Much of this chapter's content can be referred to as data wrangling. Data wrangling is the term often used in Machine Learning (ML). We are not changing any AoAs. We are simply grabbing, slicing, and consolidating the data in order to simplify subsequent analyses.
Why do we need new algorithms to combine data from different probes together?
Because we don't know which blade arrived at each probe first.
To illustrate this point, Figure 1 shows an animation of a 5 blade rotor. The rotor completes one revolution. Three proximity probes are located at different circumferential positions. Each time a blade passes a probe, we allocate the blade on the right hand side. This allows us to visualize the order in which the blades arrive at each probe. The blades have been marked with numbers 1 to 5.
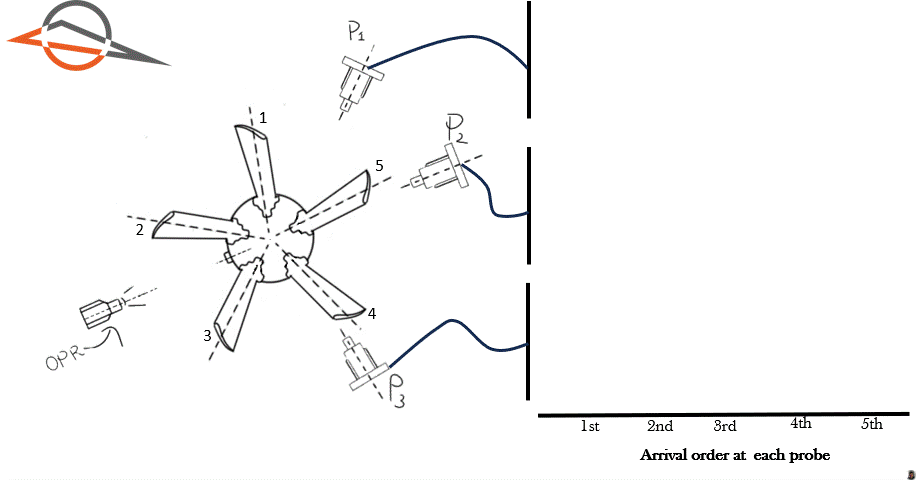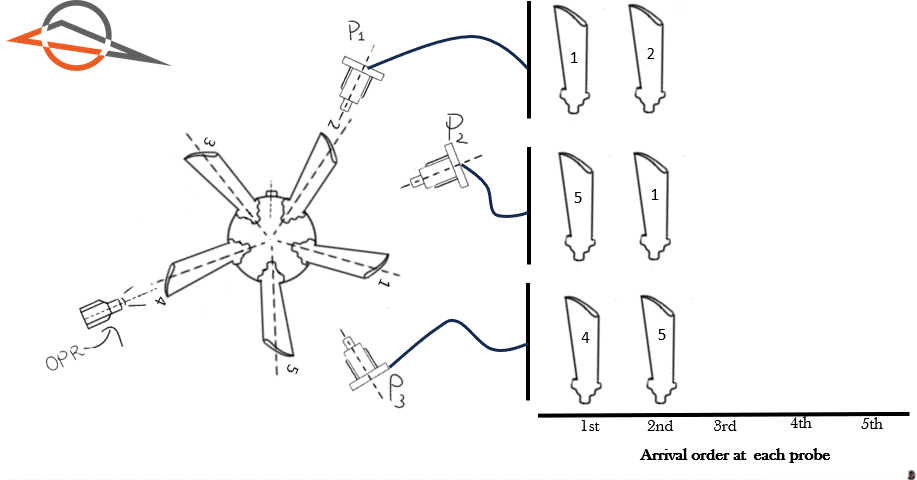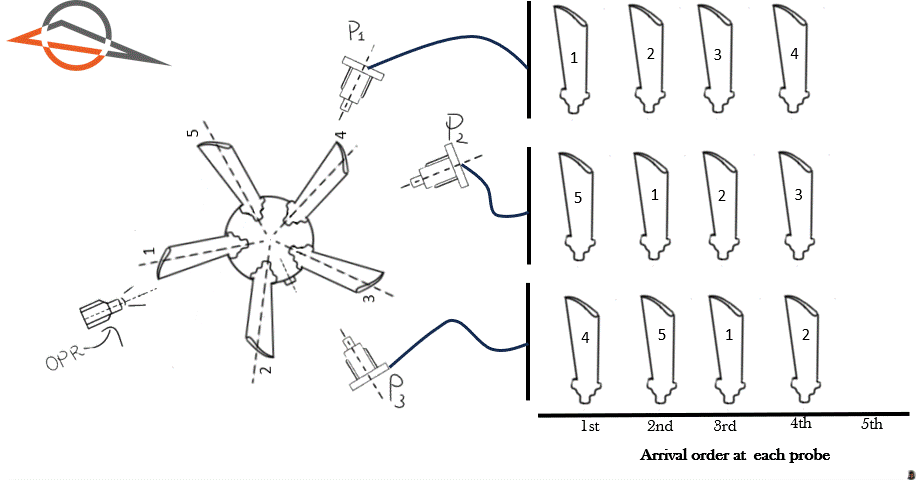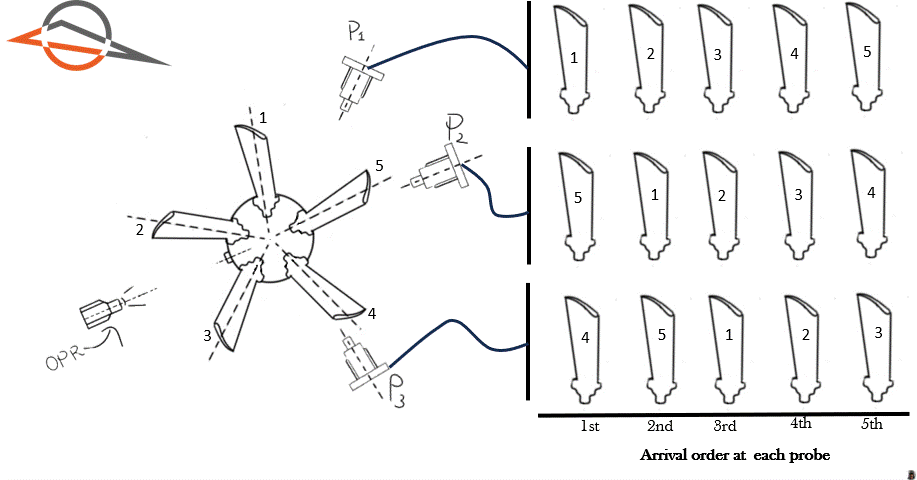
Figure 1 above demonstrates the first blade to arrive at each probe is different. The first blade to arrive at probe 1 is Blade 1. The first blade to arrive at probe 2 is Blade 5. The first blade to arrive at probe 3 is Blade 4.
It may seem simple to determine this order, but if your rotor has many blades, it is nontrivial.
A colorful example
Let's use a colorful example to illustrate the problem.
Suppose you're measuring the lap times of 5 marathon runners. Normally, you simply stand at the finish line and record the time each runner finishes.
But our race is different.
The runners do not start at the same location around the track. We can therefore not infer that the first runner to arrive at the finish line is the fastest. Each runner's starting position needs to be taken into account as well.
Furthermore, we grab two friends and disperse ourselves to arbitrary positions around the track. No one is taking measurements at the finishing line, but rather at random locations. To infer how fast the runners are going, we need to communicate with one another, and take the relative distance between all timers into account. This chapter solves a similar problem for BTT.
To collect all AoAs for the first blade, we have to "grab" the first AoA vector from probe 1, the second AoA vector from probe 2, and the third AoA vector from probe 3. To isolate the AoAs that belong to the second blade, we take the second AoA vector from probe 1, the third AoA vector from probe 2, and the fourth AoA vector from probe 3. This task is simple because the order in which the blades arrive is known for this example.
Normally, the blade order is unknown. This chapter discusses how to determine this order. By the end of this chapter, we will have one DataFrame per blade. Each DataFrame consolidates the AoAs for a single blade across all the probes.
We break this process into two steps. The two steps are explained with the help of Figure 2 below.

In the first step, we pivot the AoA vectors from each probe into a matrix where each row of the matrix represents a shaft revolution, and each column represents a blade's arrival AoA at the probe. The illustrative example includes three sensors and five blades. After step 1, there are three matrices. Each matrix corresponds to a sensor. The matrix contains 5 columns, each one holding the AoAs for a different blade.
Note that, at the end of step 1, we have not combined or considered the relationship between sensors yet. Step 2 deals with how to combine information from different sensors together. In step 2, we flex our data wrangling muscles to identify which columns in the pivoted matrices represent the same blade for each sensor. Those columns are combined together into a single DataFrame. We therefore have one DataFrame per blade, with as many columns as there are sensors.
Outcomes
Understand that we can pivot the AoAs arriving at one proximity probe in a column-wise manner. Each row of the resulting DataFrame contains the AoAs for each blade in a different column.
Understand what the stack plot is, and how it can be used to confirm our blades are properly aligned.
Write functions to convert the AoAs associated with individual proximity probes into consolidated rotor blade DataFrames containing all the ToAs and AoAs belonging to a blade.
Follow along
The worksheet for this chapter can be downloaded here .
You can open a Google Colab session of the worksheet here: ![]() .
.
You need to use one of these Python versions to run the worksheet:
![]()
![]()
![]()
Step 1: Pivot the AoA vectors for each probe

Figure 3 above shows the first step of the two-step process. We pivot the AoA vectors from each probe into a matrix where each row of the matrix represents a shaft revolution, and each column represents a blade's AoAs at the probe.
We still only consider data from a single probe at a time
We cannot stress enough that, in step 1, we still only consider data from one probe at a time. Information from different probes will be combined in step 2.
We repeat what was achieved in the previous chapter in Figure 4 below. This clarifies the transformation required in Step 1.
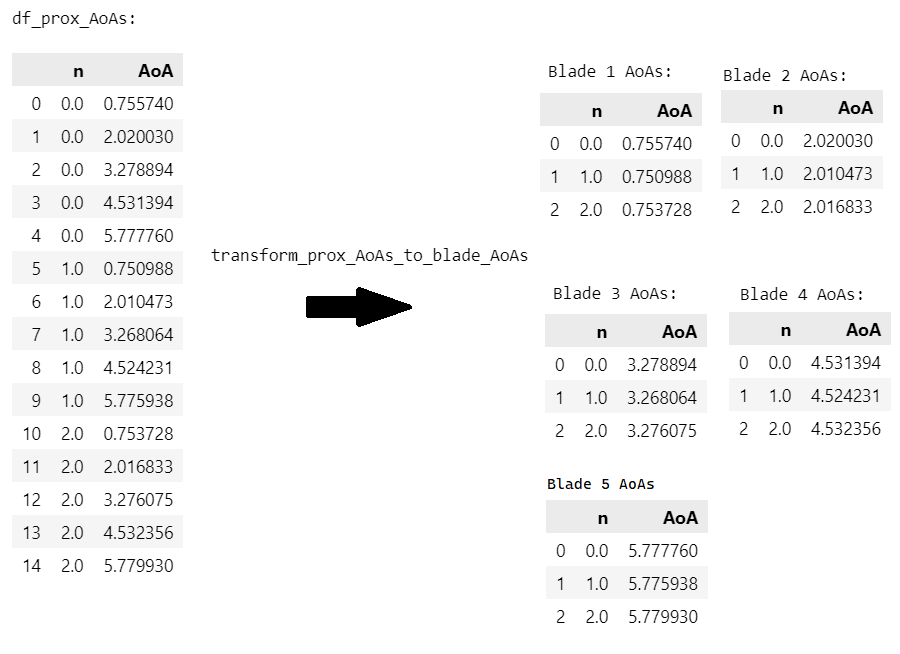
In Figure 4 above, the AoAs from one proximity probe have been sliced into 5 DataFrames. Each DataFrame represents the vector of AoAs for one blade.
Now, in step 1 of our process, we pivot those vector DataFrames into a matrix. The AoAs from different blades are located in different columns of the matrix. In other words, each row of our resulting DataFrame concatenates all the AoAs for each sensor. We want to perform the transformation illustrated in Figure 5 below.
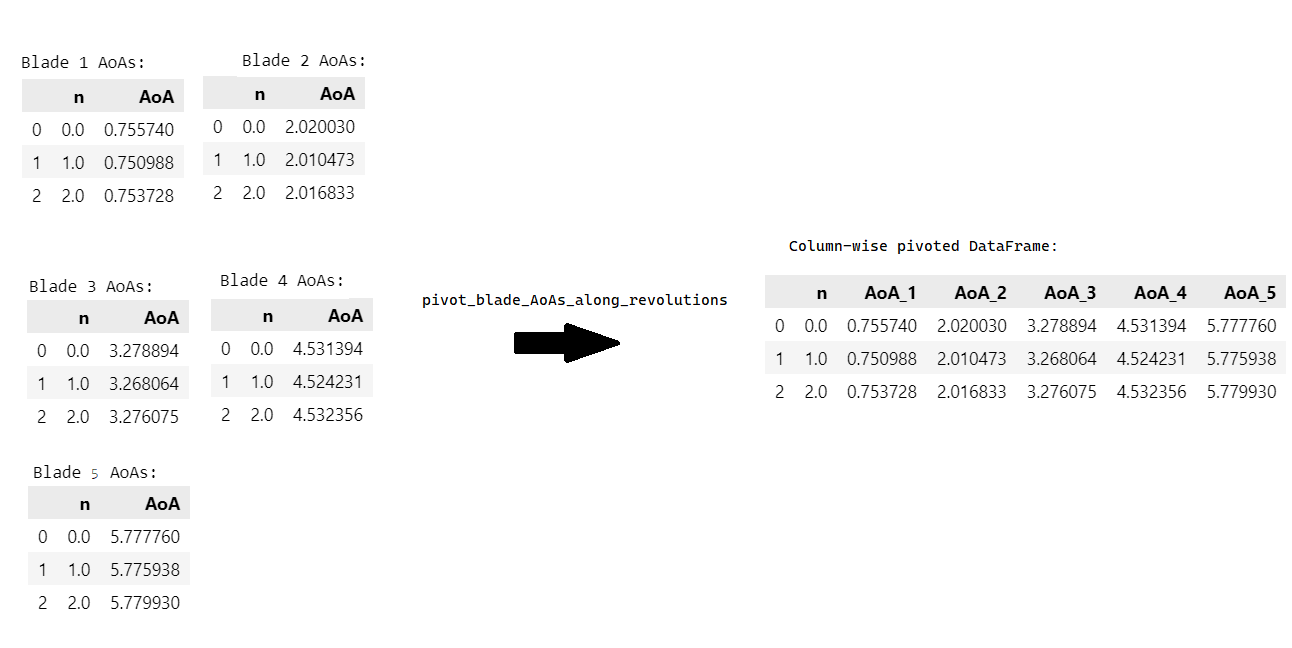
In Figure 5 above 👆, a function called pivot_blade_AoAs_along_revolutions transforms the list of DataFrames into one DataFrame. Each row contains the AoAs for each blade. We have not changed the information inside the DataFrame, merely rearranged it.
Why do we do this? Simply because its easier to work with one DataFrame than with a list of DataFrames. There are other ways to perform the work discussed in this chapter. I believe this is the most intuitive way.
The function to perform this transformation is given below. I have added code annotations to explain the steps in the function. You open them with the symbols. If the comments don't appear, refresh the page and try again.
-
The
prox_AoA_dfsis a list of DataFrames from one proximity probe where each element in the list represents the AoA values from one blade. This list is the output of thetransform_prox_AoAs_to_blade_AoAsfrom the previous chapter.The
Listtype hint is used to indicateprox_AoA_dfsis a list of DataFrames. You can import theListtype hint from thetypingmodule as such:from typing import List -
We take the first blade as our reference. We will align the other blades to the first blade's DataFrame.
-
We rename the
ToAandAoAcolumns toToA_1andAoA_1respectively. The1indicates these values belong to the first blade. -
We loop over the rest of the blades. We merge each successive blade's DataFrame into the reference DataFrame.
-
The Pandas
.mergemethod joins two DataFrames on a common key. Here, we merge the reference DataFrame with the current blade's DataFrame. We rename theToAandAoAcolumns toToA_{i+2}andAoA_{i+2}respectively. Thei+2is used because theicounter starts at zero. The first DataFrame we merge into the reference must, however, be 2. Therefore, we add 2 to theicounter. -
We perform an
outerjoin. This means we retain all rows from both DataFrames, even if no matching value for thenkey is present in one of them. If, for instance, thenfor revolution 50 is missing from the current blade's DataFrame, theToA_2andAoA_2columns will be filled withNaNvalues. -
We join the DataFrames on the
nkey,nis the revolution number.
In the above code block, the first blade's DataFrame is used as the reference DataFrame. Why do we handle the first blade's vector outside of the loop, and the other blades' vectors inside the loop? Because we need a first DataFrame to merge the other DataFrames into. If we tried to process the first blade's AoAs inside the loop, our merge operation would fail, because there is no initial DataFrame to merge it into! The first blade's AoAs are therefore treated as a special case. The first blade's AoAs become the reference into which the other blades' AoAs are merged.
Is it not arbitrary to use blade 1 as the reference?
Yes it is. We could have selected any blade as our reference. They are all equally arbitrary. Given this fact, we may as well standardize on the first blade as the reference.
Each subsequent blade's DataFrame is merged into this reference. This is a common operation in most tabular-data based applications. We expand the reference DataFrame by two columns with each merge.
The top of the merged DataFrame is presented in Table 1 below.
| n | n_start_time | n_end_time | Omega | ToA_1 | AoA_1 | ToA_2 | AoA_2 | ToA_3 | AoA_3 | ToA_4 | AoA_4 | ToA_5 | AoA_5 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.0934028 | 0.363933 | 23.2255 | 0.136547 | 1.00205 | 0.190927 | 2.26504 | 0.245069 | 3.5225 | 0.298838 | 4.77132 | 0.352618 | 6.0204 |
| 1 | 0.363933 | 0.630815 | 23.5429 | 0.40623 | 0.995802 | 0.459719 | 2.25507 | 0.513109 | 3.51203 | 0.566314 | 4.76465 | 0.619614 | 6.01947 |
| 2 | 0.630815 | 0.894334 | 23.8435 | 0.672717 | 0.999073 | 0.725672 | 2.26171 | 0.778447 | 3.52004 | 0.830988 | 4.7728 | 0.883363 | 6.0216 |
| 3 | 0.894334 | 1.15268 | 24.3212 | 0.935346 | 0.99748 | 0.987122 | 2.25673 | 1.03872 | 3.51172 | 1.09019 | 4.76346 | 1.1418 | 6.01879 |
| 4 | 1.15268 | 1.40862 | 24.5488 | 1.19335 | 0.998545 | 1.24479 | 2.26135 | 1.29604 | 3.51946 | 1.34702 | 4.77088 | 1.39792 | 6.02033 |
Column explanation 👇
| Column name | Explanation |
|---|---|
| n | The revolution number in which the blade arrived at the probe. Revolution number 0 is the first revolution. |
| n_start_time | The zero-crossing time at which the revolution started. |
| n_end_time | The zero-crossing time at which the revolution ended. |
| Omega | The shaft speed within the revolution. In units of radians/second. |
| ToA_1 | The ToA of the first blade to arrive at the probe in revolution \(n\). |
| AoA_1 | The AoA corresponding to the first ToA in revolution \(n\) as determined in Ch3. |
| ToA_2 | The ToA of the second blade to arrive at the probe in revolution \(n\). |
| AoA_2 | The AoA corresponding to the second ToA in revolution \(n\) as determined in Ch3. |
| ToA_3 | The ToA of the third blade to arrive at the probe in revolution \(n\). |
| AoA_3 | The AoA corresponding to the third ToA in revolution \(n\) as determined in Ch3. |
| ToA_4 | The ToA of the fourth blade to arrive at the probe in revolution \(n\). |
| AoA_4 | The AoA corresponding to the fourth ToA in revolution \(n\) as determined in Ch3. |
| ToA_5 | The ToA of the fifth blade to arrive at the probe in revolution \(n\). |
| AoA_5 | The AoA corresponding to the fifth ToA in revolution \(n\) as determined in Ch3. |
The table presents the ToA and AoA columns for each blade. Each row of the table contains the data for a revolution. This DataFrame is now ready for further analysis.
The stack plot
We now introduce the stack plot, a widely recognized tool in BTT. The stack plot visually represents the relative distance between adjacent blades as they pass a proximity probe. A visual representation of what the stack plot represents is provided in Figure 6 below.

Ideally, the circumferential distance between each set of adjacent blades would be the same. In reality, each rotor exhibits a unique pattern of blade spacing. We can use this unique pattern to assess whether our alignment has been done properly.
In the example above, the consecutive distances between adjacent blades for the first shaft revolution is:
- The
iloc[0]method is used to access the first row of the DataFrame. It returns a Pandas Series, and we can access theAoAcolumns with the[]operator.
blade_2_minus_1: 1.2629980304819501 rad
blade_3_minus_2: 1.2574606040202596 rad
blade_4_minus_3: 1.2488114790250116 rad
blade_5_minus_4: 1.2490816162460137 rad
blade_1_minus_5: 1.2585900251951907 rad
Stack plot calculations are intuitive: Blade 1's AoA in revolution n is subtracted from Blade 2's AoA in revolution n, Blade 2's AoA in revolution n is subtracted from Blade 3's AoA in revolution n, and so on. The only tricky calculation is the blade_1_minus_5 calculation. Here, we subtract the AoA of the first blade from the second revolution (n=1) from the AoA of the last blade from the first revolution (n=0). Put another way: the blade to arrive after the last blade of the first revolution is the first blade in the second revolution.
Here's a function called create_stack_plot_df to calculate the stack plot:
- To start, we collect all the columns with the prefix
AoA_. This will return as many columns as there are blades. - The number of blades,
B, is calculated from the AoA column headings. - We initialize a dictionary that will contain the stack plot values. We use a dictionary because it is easy to convert it to a Pandas DataFrame later on with the
pd.DataFrameconstructor. - We add the revolution number to the DataFrame. This is the only column that is not a stack plot value. We don't use
nin the stack plot, but it feels wrong to throw away the revolution number column .
. - We iterate over all the blades except the last blade. We therefore use
range(B - 1)instead ofrange(B). Within this loop, we calculate the difference between adjacent blade pairs. We'll calculate the difference between the last and the first blade after the loop has executed. - We get the column name of the blade to arrive second - i.e. after the first one.
- The name of the column that corresponds to the first blade.
- We calculate the difference between the two blades. We use the
.to_numpy()method to convert the Pandas Series to a NumPy array. We do this to get rid of ourPandasindex. - We add the blade difference array to the dictionary.
- We now calculate the stack plot values between the last blade and the first blade. The farthest blade is the first blade and the closer blade is the last blade.
- Here we subtract the two from one another. Note there's a difference between the revolution numbers of the two arguments. The farthest blade starts at the second revolution, and the closer blade starts at the first revolution. Also note the
+ 2 * np.piaddition. It wraps the AoAs from the first blade back to the previous revolution. - We need to add one
Nonevalue to the last blade's stack plot values because its dimension must match the other stack plot columns. - We convert the dictionary that holds our values in a Pandas DataFrame and return it.
We now can calculate the median of each column. We use the .median method:
n is meaningless here, and will not be plotted.
Figure 7 below shows the median stack plot values for each blade. To help interpret the y-axis, recall the ideal distance between each blade is \(\frac{2 \pi}{5} \approx 1.256637\).
In Figure 7 above, the median difference between consecutive blades are all approximately equal to the ideal distance of \(\frac{2 \pi}{5}=1.256637\). The differences that do exist, however, are valuable, and can be considered a "fingerprint" for this rotor.
We've now figured out how to determine the stack plot for one probe. The stack plot values for all the probes are displayed on top of one another in Figure 8 below. This is simply a formality. We expect the stack plot for each probe to be identical because the same blades arrive at each probe. We expect all the lines to lie neatly on top of one another.
Oh no! 
The stack plots are clearly different. How can this be? How can the rotor suddenly change shape based on the probe?
The rotor has not changed shape.
The stack plot, as we've shown at the start of the chapter in Figure 1, is a function of which blade arrives first at each probe. The stack plot for probe 1 is different from the stack plot for probes 2, 3 and 4 because the first blade to arrive at probe 1 is not the same blade as the first blade to arrive at probes 2, 3 and 4.
Difference between arrival order of Figure 1 vs arrival order of Figure 8
Please note the arrival order of the blades in Figure 1 is not the same as the arrival order in Figure 8. Figure 1's arrival order was chosen to vividly illustrate the fact that different blades arrive at different probes first. The arrival order in Figure 8 is the actual arrival order of the blades for our dataset.
Step 2: Combine the pivoted DataFrames from different probes

The first blade to arrive at probe number 1 and the first blade to arrive at probes 2, 3 and 4 is not the same blade. This causes the stack plot for probes 2, 3 and 4 to seem shifted. We can visually inspect the stack plot to determine how much the stack plot for probes 2, 3 and 4 is shifted.
A nice way to visualize this is to plot the stack plot on a polar plot.
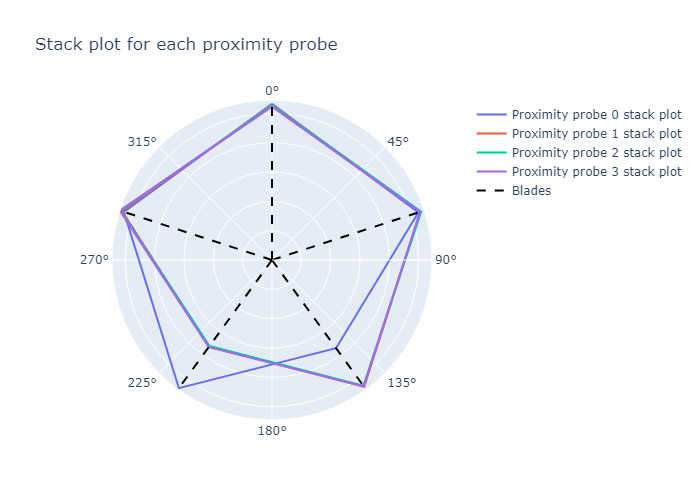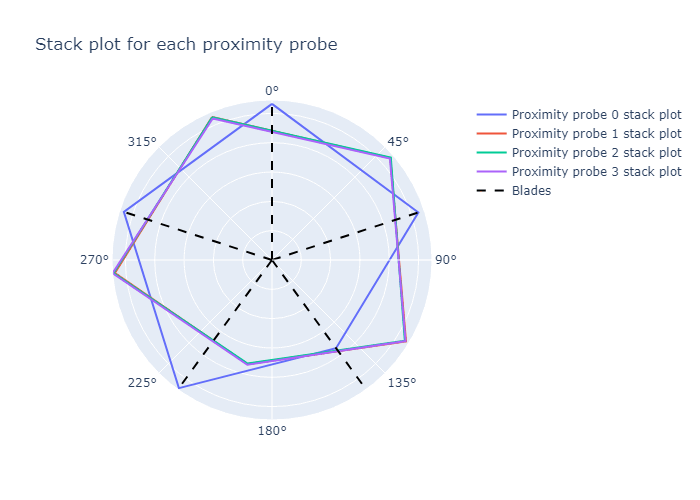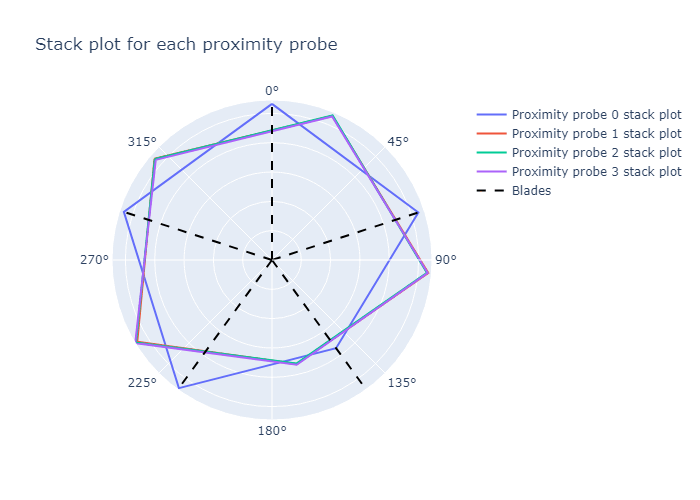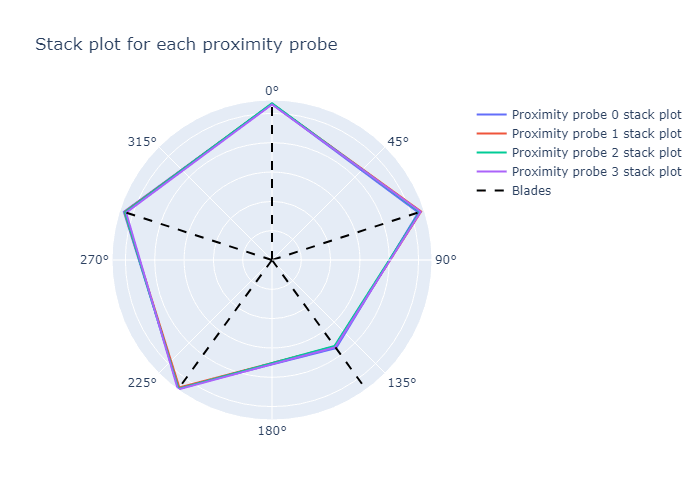
The first probe's stack plot is kept constant. Probe 2, 3, and 4's stack plots are shifted by \(\frac{360}{5} = 72\) degrees counterclockwise. This is the same as shifting the stack plot by 1 blade. The stack plot for probes 2, 3 and 4 now matches the stack plot for probe 1.
Rename the columns for global alignment
The simplest way to solve our apparent conundrum is to rename the columns from the probe 2, 3 and 4 stack plot DataFrames such that it results in a stack plot similar to the first probe.
In our case, the below transformation must be performed.
Default order
_____________________________________________
["AoA_1", "AoA_2", "AoA_3", "AoA_4", "AoA_5" ] # Start with each default order
["AoA_1"] + ["AoA_2", "AoA_3", "AoA_4", "AoA_5"] # Break the list into 2 lists
["AoA_2", "AoA_3", "AoA_4", "AoA_5"] + ["AoA_1"] # Switch the the lists around
["AoA_2", "AoA_3", "AoA_4", "AoA_5", "AoA_1" ] # Add them again
_____________________________________________
Probe 2, 3 and 4 order # 👈 This is the global blade order
# for probes 2, 3, and 4
- Before we perform the shift, we confirm the user is not trying to shift the column headings by more than the number of blades. This would not make sense!
- We separate our columns at the
shift_byindex and concatenate the two parts in reverse order. We wrap theaoa_column_headingswith thelistfunction. This is not strictly necessary if the user uses a Python list as the type foraoa_column_headings, but some people may want to passaoa_column_headingsas a Pandas series or a NumPy array. These constructs only implement the '+' to mean mathematical addition, not list concatenation.
We demonstrate the shift function below:
Shift by 0: ['AoA_1', 'AoA_2', 'AoA_3', 'AoA_4', 'AoA_5']
Shift by 1: ['AoA_2', 'AoA_3', 'AoA_4', 'AoA_5', 'AoA_1']
Shift by 2: ['AoA_3', 'AoA_4', 'AoA_5', 'AoA_1', 'AoA_2']
Shift by 3: ['AoA_4', 'AoA_5', 'AoA_1', 'AoA_2', 'AoA_3']
Shift by 4: ['AoA_5', 'AoA_1', 'AoA_2', 'AoA_3', 'AoA_4']
How much should we shift the column headings?
Excellent, you've spotted a gap in my approach. Until now, we've been able to estimate the shift directly from the stack plot. This is not ideal. We're almost at the point where we write a function to estimate the shift. We'll do this in the next section.
This function can be used to rename the columns:
- The DataFrame that we want to change.
- The column headings to which the columns in
df_to_alignshould be mapped. This will normally be AoA or ToA column headings. - The number of positions to shift the column headings by.
- We return a DataFrame with the exact same shape and column headings as
df_to_align, but with the column headings renamed and re-ordered. Some columns indf_to_alignshould not be sorted or renamed, such as the revolution numbern. We need to return these columns as is. - We shift the column headings of the
global_column_headingsbyshift_bypositions. - We create a dictionary that maps the column headings in
df_to_alignto theglobal_column_headings. Thezipfunction allows us to iterate over theshifted_dataframe_columnsand theglobal_column_headingstogether. - We store the original column order of
df_to_alignin a variable. We will use this to re-order the columns indf_to_alignin the return statement. - We rename the columns in
df_to_alignwith thecolumn_headings_to_renamedictionary. - We return the columns in
df_to_alignin the original order.
The stack plots are now redrawn in Figure 11 below.
Perfect  !
!
Our stack plots for all probes lie on top of one another. We can therefore conclude our alignment is correct. Small differences between the median stack plot values for the different probes are observed. We attribute the differences to random noise and manufacturing tolerances in the axial and radial positions of the probes. Each probe therefore reacts slightly differently to the presence of the blades.
Calculate the shift based on probe spacing
We've successfully shifted the stack plot DataFrames to align them all with the first probe. We estimated the amount to shift through visual inspection of the stack plot. This estimation is simple if the rotor only has 5 blades.
Normally, however, you cannot eyeball this shift for a rotor with more blades. We therefore need to estimate the shift based on the installed spacing between the probes.
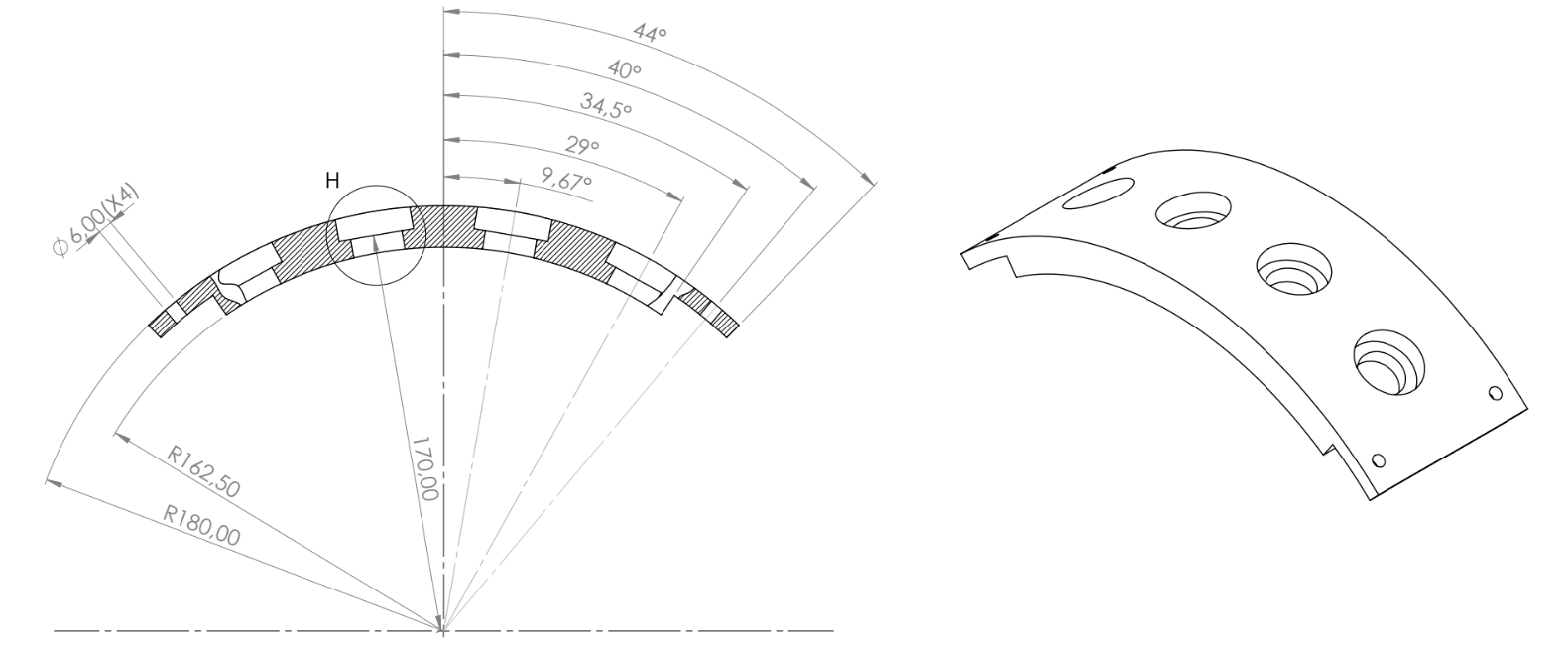
The engineering drawing for the probe holder used in the current dataset reveals the spacing between the probes in Figure 12 below.
Equidistant vs non-equidistant spacing
How would our method differ between equidistant and non-equidistant probe sets? Nothing. The present method works for any probe-spacing.
From Figure 12 above, the holes for the probes were manufactured to be 19.34 degrees from one another.
In reality, because of manufacturing tolerances, the manufactured spacing will be slightly different. Even if you could manufacture it perfectly, the probes themselves may still not "respond" perfectly similar. This would lead to AoAs that do not correspond to the centerline of the intended probe locations.
We therefore need to assume the probes are not perfectly spaced. We therefore need an algorithm to determine when each blade arrives at each probe.
We follow a two step process to achieve this:
-
Predict the likely AoA of a blade at a subsequent probe based on:
-
the AoA of the blade at the current probe and;
-
the spacing between the two probes.
-
-
Determine which AoA value in the subsequent probe's DataFrame is closest to the predicted AoA value.
Here's a function that performs the first step:
- The DataFrame that contains the AoAs for the probe for which you want to determine the offset. This DataFrame is the result of the
pivot_blade_AoAs_along_revolutionsfunction. - Our initial AoA. This will always be the median AoA of the first blade to arrive at probe 1.
- The relative distance between the probe responsible for measuring the values in
df_probe_AoAsand the probe from whichstarting_aoawas obtained. The distance must be provided in radians. - The function returns the offset required for the AoA columns in
df_probe_AoAsto align it to the blade fromstarting_aoa. - We add the relative distance between the probes to the initial AoA. This gives us the predicted AoA of the blade at the later probe.
- We wrap the predicted AoA value to the range \([0, 2 \pi)\). This is to cater for cases where a blade arrives at
starting_aoain the next revolution. - We get all the AoA column headings from
df_probe_AoAs. - We calculate the median AoA for each blade at the current probe.
- We calculate the absolute error between the predicted AoA and the median AoA for each blade.
- The
np.argminreturns the index of the smallest entry in an array. In this case, the smallest value inerr_aoawill correspond to the blade that arrives closest topredicted_blade_position.
We can use the function above to check our previous assumption: the offset for probes 2, 3, and 4 must be 1.
- We calculate the median AoA of the first blade to arrive at probe 1. We consider it our first probe's AoA.
- We calculate the relative distance between the probes. We use the
np.deg2radfunction to convert the degrees to radians. - We iterate over the DataFrames for each probe. The
enumeratefunction returns the index of the current iteration,i, and the current probe AoA DataFrame and probe spacing. - We use the
zipfunction to iterate over the DataFrames and the probe spacings together. This is a common pattern in Python. - We use the
predict_probe_offsetfunction to determine the offset for the current probe. We use the median AoA of the first blade arriving at probe 1 as the initial AoA. - We print the offset for the current probe.
The optimal offset for probes 2, 3 and 4 is indeed 1. We have also calculated the optimal offset for probe 1. This is simply a sanity check, and should always return 0.
Assemble global blade DataFrames
We now finally assemble one dataframe for each blade. The dataframes will contain the AoAs for each blade across all the probes.
A function that constructs B DataFrames from each of the pivoted proximity probe DataFrames is presented below.
- We get all the AoA column headings from the first DataFrame in
prox_aligned_dfs. We use the first DataFrame because all the DataFrames inprox_aligned_dfshave the same column headings. - Similar to the above line, we get the ToA column names.
- We get all the column headings that are not AoA or ToA headings, such as
n,n_start_time,n_end_time, andOmega. - We determine the number of blades in the rotor.
- We determine the number of proximity probes.
- This is a sanity check to ensure we've provided the correct number of probe spacings.
- We initialize an empty list that will contain the rotor blade DataFrames.
- The purpose of this loop is to get the AoA and ToA values from the first probe. This is the start of each rotor blade's AoA DataFrame and will be grown to include the other proximity probe values in the next loop.
- We determine the column headings needed to copy from the first probe's DataFrame. We need to copy a) all the columns that are not AoA or ToA columns, and b) the AoA and ToA columns for only the current blade.
- We construct the dictionary to be used with Pandas'
.renamefunction to rename the AoA and ToA column headings. - We copy the columns from the first probe's DataFrame and rename the AoA and ToA columns for the current blade to
AoA_p1andToA_p1respectively. We append the DataFrame to therotor_blade_dfslist. - We determine the median AoA of the first blade at the first probe. We will use this value to predict the AoA of the first blade at the other probes.
- We loop over the rest of the probes and their probe spacings. Note the probe spacings are all relative to the first probe.
- We determine the probe number. This is simply the iterator value plus 2, since the first probe is probe 1. We create this variable for renaming purposes.
- We calculate the offset for the current probe. We use the
predict_probe_offsetfunction we wrote earlier. - We rename the AoA columns in
df_probe_AoAsto align them with the first probe. We use therename_df_columns_for_alignmentfunction we wrote earlier. - Now we rename ToA columns in
df_probe_AoAs. - We merge our aligned probe's AoA DataFrame,
df_probe_AoAs_aligned, with the current blade's DataFrame. We use themergefunction to do this. We use theoutermerge type to ensure we do not lose any data. We merge on the revolution numbern.
We can use this function to get a list of rotor blade DataFrames:
- We use the
np.cumsumfunction to calculate the cumulative spacing between each probe and the first probe. This is because we specify our probe spacings in its increments between subsequent probes, not in absolute terms. - We convert the probe spacings to radians. We use this function instead of multiplication with
np.pi/180 . This makes it exceedingly unlikely we'll make a mistake with this conversion. - We specify the probe spacings between adjacent probes from Figure 6.
The first three rows in the rotor blade AoA DataFrame is shown in Table 2 below.
| n | n_start_time | n_end_time | Omega | ToA_p1 | AoA_p1 | ToA_p2 | AoA_p2 | ToA_p3 | AoA_p3 | ToA_p4 | AoA_p4 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.0934028 | 0.363933 | 23.2255 | 0.136547 | 1.00205 | 0.180378 | 2.02003 | 0.180378 | 2.02003 | 0.180378 | 2.02003 |
| 1 | 0.363933 | 0.630815 | 23.5429 | 0.40623 | 0.995802 | 0.449329 | 2.01047 | 0.449329 | 2.01047 | 0.449329 | 2.01047 |
| 2 | 0.630815 | 0.894334 | 23.8435 | 0.672717 | 0.999073 | 0.715402 | 2.01683 | 0.715402 | 2.01683 | 0.715402 | 2.01683 |
From Table 2 above, four AoA columns and four ToA columns are displayed, one for each probe. We can also identify the probe by its subscript p. This DataFrame shares similarities with the DataFrame shown in Table 1.
To get a better perspective on what we've done, we present, in Table 3 below, the last rotor blade's AoA DataFrame.
| n | n_start_time | n_end_time | Omega | ToA_p1 | AoA_p1 | ToA_p2 | AoA_p2 | ToA_p3 | AoA_p3 | ToA_p4 | AoA_p4 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.0934028 | 0.363933 | 23.2255 | 0.352618 | 6.0204 | 0.125942 | 0.75574 | 0.125942 | 0.75574 | 0.125942 | 0.75574 |
| 1 | 0.363933 | 0.630815 | 23.5429 | 0.619614 | 6.01947 | 0.395832 | 0.750988 | 0.395832 | 0.750988 | 0.395832 | 0.750988 |
| 2 | 0.630815 | 0.894334 | 23.8435 | 0.883363 | 6.0216 | 0.662427 | 0.753728 | 0.662427 | 0.753728 | 0.662427 | 0.753728 |
Note that ToA_p1 in the first row occurs after the other ToAs in the same row. The first probe, therefore, that observes blade 5 in every revolution is probe number 2, and the last probe to observe it is probe number 1.
Conclusion
We've done a lot of work in this chapter that yielded one DataFrame per blade. The steps involved are numerous and may be confusing. Rest assured, it gets easier with practice. The first coding exercise 👇 below will challenge you to combine everything we've done until now in a single function to get the rotor blade DataFrames.
We've now reached the peak of the difficulty mountain of BTT. From here, we can start doing the "cool" stuff. The stuff most published work is about.
We can start doing vibration analysis.
Outcomes
Understand that we can pivot the AoAs arriving at one proximity probe in a column-wise manner. Each row of the resulting DataFrame contains the AoAs for each blade in a different column.
Understand what the stack plot is, and how it can be used to confirm our blades are properly aligned.
Write functions to convert the AoAs associated with individual proximity probes into consolidated rotor blade DataFrames containing all the ToAs and AoAs belonging to a blade.
Acknowledgements
Thanks to Justin Smith and Alex Brocco for reviewing this chapter and providing feedback.

Dawie Diamond
2024-02-28
Coding exercises
1. One function to rule them all
We've done a lot of work in chapters 3, 4 and 5. Its now time to combine them into one function that receives raw time stamps, and returns rotor blade AoA DataFrames.
Write a function called get_rotor_blade_AoAs that receives the these three inputs:
- A DataFrame that contains the opr zero-crossing times.
- A list of ToAs from each proximity probe.
- A list of probe spacings between each proximity probe and the first proximity probe.
and returns a list of rotor blade DataFrames. I recommend you leverage the functions we've written in this chapter.
Reveal answer (Please try it yourself before revealing the solution)
Usage example:
2. Predict the probe spacings
It can happen that you receive a set of BTT timestamps, but the exact probe spacing is unknown. This can happen when you are handed an old dataset. It can also happen because you're not 100% sure that the manufactured probe spacing is correct.
Write a function that calculates the probe spacing by comparing the stack plot between two probes.
Reveal answer (Please try it yourself before revealing the solution)
 BOO.
BOO.
I'll leave you to it. I actually think this could make a journal publication. If you're stuck, you can reach me at dawie.diamond@bladesight.com.